import arviz as az
import numpy as np
import pandas as pd
import pymc as pm
from matplotlib import pyplot as plt
from patsy import dmatrix
import causalpy as cp
## Setting for Mac OS spawning multi-process defaults on M1 chip
sampler_kwargs = {
"tune": 2000,
"draws": 2000,
"target_accept": 0.95,
"mp_ctx": "spawn",
"random_seed": 1040,
}
The Paradox of Propensity Scores in Bayesian Inference#
In causal inference the role of the propensity score is often seen to be central. For instance, we’ve seen how the propensity score can be used with the cp.InversePropensityWeighting class to correct for a species of selection bias by re-weighting our outcome variable and calculating a causal contrast on the re-weighted scale. Additionally we can use the propensity score to visualise and diagnose problems of overlap or covariate balancing across treatment and control groups.
These properties give the propensity score a large role to play in design based approaches to causal inference. The focus there is on assessing aspects of the treatment allocation to ensure we have identifiability assurances for estimands of interest. What then is their role in model-based or analysis focused Bayesian methods?
When we use cp.InversePropensityWeighting to apply various re-weighting techniques we perform a two-step manoeuvre: 1. we estimate the propensity score and 2. apply the inverse-weighting of the score to transform our outcome variable and assess causal contrasts. But being good Bayesians, we might wonder why go to all this trouble? Can we not simply estimate a full-bayesian model of treatment and outcome simultaneously?
In this notebook we’ll show why we should be careful attempting to model the joint-distribution of the propensity score and the outcome variable, but still make good use of the propensity score.
Brief Digression on the Mathematics#
Consider that we have the following three variables:
where \(Y\) is our outcome variable, \(T\) is our treatment variable, and \(X\) stands in for all other control variables in scope. Now define the propensity score
and our outcome model
but now it’s clearer to see how the propensity score just cancels out. When we’re already conditioning on \(X, T\) the information in the propensity score is technically redundant in the Bayesian setting. Add the assumption of unconfoundedness or ignorability used in causal inference. We are arguing that there is no umeasured confounding so conditioning on \(X, T\) should be sufficient to identify the causal contrast of interest.
Structure of the Presentation#
We will first consider a simple simulated data set where we know the true values of the data generating process and then we’ll demonstrate how to fit the joint distribution of the propensity score and the outcome in a single joint distribution using PyMC. To contrast this we’ll show how to fit a two-stage version of the same model. In both models we assume independent priors between the regression for the treatment and the regression for the outcome variable. Nevertheless, we will show that the joint model exhibits a bias due to feedback when there is non-measured confounding i.e. when there is misspecified outcome model.
Model Specification
Specifying the Joint ModelSpecifying the 2 Stage Model
Application to Simulated Outcome
Application to Mosquito Net Data
Application to Lalonde Data
Application to NHEFS data.
Note the presentation here owes a debt to the work of Fan Li in [Fan et al., 2023] and her presentation here. Additionally we drew on the work and data of Andrew Heiss here and Jordan Nafa and Andrew Heiss here.
Generate Some Data#
N = 4000
np.random.seed(1043)
def inv_logit(z):
"""Compute the inverse logit (sigmoid) of z."""
return 1 / (1 + np.exp(-z))
df1 = pd.DataFrame(
{
"x1": np.random.normal(0, 1, N),
"x2": np.random.normal(0, 1, N),
"x3": np.random.normal(0, 1, N),
}
)
TREATMENT_EFFECT = 2
df1["trt"] = np.random.binomial(1, inv_logit(df1["x1"] + 6 * df1["x2"] + 7 * df1["x3"]))
df1["outcome"] = (
1
+ TREATMENT_EFFECT * df1["trt"]
+ df1["x1"]
+ 0.2 * df1["x2"]
+ -3 * df1["x3"]
+ np.random.normal(0, 1, N)
)
df1.head()
| x1 | x2 | x3 | trt | outcome | |
|---|---|---|---|---|---|
| 0 | 0.570753 | -1.372992 | 0.247824 | 0 | 1.114661 |
| 1 | 0.063973 | 0.904728 | 0.322222 | 1 | 2.952142 |
| 2 | -0.356653 | -0.188922 | -1.369041 | 0 | 5.809954 |
| 3 | -1.372285 | -0.611158 | -1.755242 | 0 | 5.509733 |
| 4 | 0.029955 | 1.773686 | -0.455371 | 1 | 6.058045 |
Specifying the Joint Model#
Now we define a model context that fits our data simultaneously for treatment and outcome. We allow that the propensity score estimated in the treatment model is used in a non-parametric spline to flexibly inform the outcome variable. Note that we will allow for a richer model specification of the treatment than we do for the outcome model. This is to try and push the models to use the propensity score information to adjust for unmeasured confounding in the outcome model.
coords = {
"betas": ["trt", "x1"],
"betas_trt": ["x1", "x2", "x3"],
"obs": range(df1.shape[0]),
}
N = df1.shape[0]
X_trt = df1[["x1", "x2", "x3"]].values
X_outcome = df1[["trt", "x1"]].values
T_data = df1["trt"].values
Y_data = df1["outcome"].values
def make_joint_model(
X_trt,
X_outcome,
T_data,
Y_data,
coords,
priors={
"beta_": [0, 1],
"beta_trt": [0, 1],
"alpha_trt": [0, 1],
"alpha_outcome": [0, 1],
"sigma": 1,
"beta_ps": [0, 1],
},
noncentred=True,
normal_outcome=True,
):
with pm.Model(coords=coords) as model:
X_data_trt = pm.Data("X", X_trt, dims=("obs", "beta_trt"))
X_data_outcome = pm.Data("X_outcome", X_outcome, dims=("obs", "betas"))
T_data_ = pm.Data("T", T_data, dims="obs")
Y_data_ = pm.Data("Y", Y_data, dims="obs")
if noncentred:
mu_beta_trt, sigma_beta_trt = priors["beta_trt"]
beta_trt_std = pm.Normal("beta_trt_std", 0, 1, dims="betas_trt")
beta_trt = pm.Deterministic(
"beta_trt_",
mu_beta_trt + sigma_beta_trt * beta_trt_std,
dims="betas_trt",
)
mu_beta, sigma_beta = priors["beta_"]
beta_std = pm.Normal("beta_std", 0, 1, dims="betas")
beta = pm.Deterministic(
"beta_", mu_beta + sigma_beta * beta_std, dims="betas"
)
else:
beta_trt = pm.Normal(
"beta_trt_",
priors["beta_trt"][0],
priors["beta_trt"][1],
dims="betas_trt",
)
beta = pm.Normal(
"beta_", priors["beta_"][0], priors["beta_"][1], dims="betas"
)
beta_ps = pm.Normal("beta_ps", priors["beta_ps"][0], priors["beta_ps"][1])
alpha_trt = pm.Normal(
"alpha_trt", priors["alpha_trt"][0], priors["alpha_trt"][1]
)
mu_trt = alpha_trt + pm.math.dot(X_data_trt, beta_trt)
p = pm.Deterministic("p", pm.math.invlogit(mu_trt), dims="obs")
pm.Bernoulli("t_pred", p=p, observed=T_data_, dims="obs")
alpha_outcome = pm.Normal(
"alpha_outcome", priors["alpha_outcome"][0], priors["alpha_outcome"][1]
)
mu_outcome = alpha_outcome + pm.math.dot(X_data_outcome, beta) + beta_ps * p
sigma = pm.HalfNormal("sigma", priors["sigma"])
if normal_outcome:
_ = pm.Normal("like", mu_outcome, sigma, observed=Y_data_, dims="obs")
else:
nu = pm.Exponential("nu", lam=1 / 10)
_ = pm.StudentT(
"like", nu=nu, mu=mu_outcome, sigma=sigma, observed=Y_data_, dims="obs"
)
return model
model = make_joint_model(X_trt, X_outcome, T_data, Y_data, coords)
pm.model_to_graphviz(model)

Note how the two likelihood terms are fit simultaneously.
Note
We are specifying the models in raw PyMC code for clarity, but we will bundle these methods into the neater CausalPy API below.
Specifying the 2 Stage Model#
Here we allow for a function that takes the same inputs but fits two separate models. First we fit the treatment model then store the idata_treatment this xarray object stores the posterior estimates for the propensity score. We pass this through to a second outcome model where we proceed to take a random draw from the posterior and pass it through to the outcome regression via a spline component. This allows us to express any non-linearity in the treatment effect. Additionally it can be seen as a way to augment the outcome model.
While theoretically the propensity score contains no extra information if we are already conditioning on \(X\), practically the literature reports that the propensity improves the stability of the causal estimates achievable in Bayesian causal modelling. Additionally we might want to separate covariates for predicting the outcome and the treatment. In this case, there may be extra information derived in the treatment model that be used to inform the outcome model.
def make_treatment_model(
X_trt,
T_data,
coords,
priors={
"beta_": [0, 1],
"beta_trt": [0, 1],
"alpha_trt": [0, 1],
"alpha_outcome": [0, 1],
},
noncentred=True,
):
with pm.Model(coords=coords) as model_trt:
X_data_trt = pm.Data("X", X_trt, dims=("obs", "betas_trt"))
T_data_ = pm.Data("T", T_data, dims="obs")
if noncentred:
mu_beta_trt, sigma_beta_trt = priors["beta_trt"]
beta_trt_std = pm.Normal("beta_trt_std", 0, 1, dims="betas_trt")
beta_trt = pm.Deterministic(
"beta_trt_",
mu_beta_trt + sigma_beta_trt * beta_trt_std,
dims="betas_trt",
)
else:
beta_trt = pm.Normal(
"beta_trt_",
priors["beta_trt"][0],
priors["beta_trt"][1],
dims="betas_trt",
)
alpha_trt = pm.Normal(
"alpha_trt", priors["alpha_trt"][0], priors["alpha_trt"][1]
)
mu_trt = alpha_trt + pm.math.dot(X_data_trt, beta_trt)
p = pm.Deterministic("p", pm.math.invlogit(mu_trt), dims="obs")
pm.Bernoulli("t_pred", p=p, observed=T_data_, dims="obs")
return model_trt
def make_outcome_model(
X_outcome,
Y_data,
coords,
priors={
"beta_": [0, 1],
"beta_trt": [0, 1],
"alpha_trt": [0, 1],
"alpha_outcome": [0, 1],
"sigma": 1,
"beta_ps": [0, 1],
},
noncentred=True,
spline_component=False,
propensity_score_idata=None,
normal_outcome=True,
winsorize_boundary=0.0,
):
propensity_scores = az.extract(propensity_score_idata)["p"]
with pm.Model(coords=coords) as model_outcome:
X_data_outcome = pm.Data("X_outcome", X_outcome, dims=("obs", "betas"))
Y_data_ = pm.Data("Y", Y_data, dims="obs")
if noncentred:
mu_beta, sigma_beta = priors["beta_"]
beta_std = pm.Normal("beta_std", 0, 1, dims="betas")
beta = pm.Deterministic(
"beta_", mu_beta + sigma_beta * beta_std, dims="betas"
)
else:
beta = pm.Normal(
"beta_", priors["beta_"][0], priors["beta_"][1], dims="betas"
)
beta_ps = pm.Normal("beta_ps", priors["beta_ps"][0], priors["beta_ps"][1])
chosen = np.random.choice(range(propensity_scores.shape[1]))
p = propensity_scores[:, chosen].values
p = np.clip(p, winsorize_boundary, 1 - winsorize_boundary)
alpha_outcome = pm.Normal(
"alpha_outcome", priors["alpha_outcome"][0], priors["alpha_outcome"][1]
)
mu_outcome = alpha_outcome + pm.math.dot(X_data_outcome, beta) + beta_ps * p
if spline_component:
beta_ps_spline = pm.Normal(
"beta_ps_spline", priors["beta_ps"][0], priors["beta_ps"][1], size=14
)
B = dmatrix(
"bs(ps, knots=knots, degree=3, include_intercept=True, lower_bound=0, upper_bound=1) - 1",
{"ps": p, "knots": np.linspace(0, 1, 10)},
)
B_f = np.asarray(B, order="F")
splines_summed = pm.Deterministic(
"spline_features", pm.math.dot(B_f, beta_ps_spline.T), dims="obs"
)
mu_outcome = (
alpha_outcome + pm.math.dot(X_data_outcome, beta) + splines_summed
)
sigma = pm.HalfNormal("sigma", priors["sigma"])
if normal_outcome:
_ = pm.Normal("like", mu_outcome, sigma, observed=Y_data_, dims="obs")
else:
nu = pm.Exponential("nu", lam=1 / 10)
_ = pm.StudentT(
"like", nu=nu, mu=mu_outcome, sigma=sigma, observed=Y_data_, dims="obs"
)
return model_outcome
def make_2step_model(
X_trt,
X_outcome,
T_data,
Y_data,
coords,
priors,
spline_component=False,
normal_outcome=True,
winsorize_boundary=0.0,
):
treatment_model = make_treatment_model(X_trt, T_data, coords, priors)
with treatment_model:
idata_treatment = pm.sample_prior_predictive()
idata_treatment.extend(pm.sample(**sampler_kwargs))
outcome_model = make_outcome_model(
X_outcome,
Y_data,
coords,
priors,
spline_component=spline_component,
propensity_score_idata=idata_treatment,
normal_outcome=normal_outcome,
winsorize_boundary=winsorize_boundary,
)
with outcome_model:
idata_outcome = pm.sample_prior_predictive()
idata_outcome.extend(pm.sample(**sampler_kwargs))
return idata_treatment, idata_outcome, treatment_model, outcome_model
model_treatment = make_treatment_model(X_trt, T_data, coords)
pm.model_to_graphviz(model_treatment)

Specifying a Simple Regression Model without Propensity Scores#
Now we specify a simple regression model which does not make use of the propensity score information. This model will be used to assess how much extra information is gleaned from the presence of the propensity score as covariate in our outcome model.
def make_reg_model(
X_outcome,
Y_data,
coords,
priors={
"beta_": [0, 1],
"alpha_outcome": [0, 1],
"sigma": 1,
},
noncentred=True,
):
with pm.Model(coords=coords) as reg_model:
X_data_outcome = pm.Data("X_outcome", X_outcome, dims=("obs", "betas"))
Y_data_ = pm.Data("Y", Y_data, dims="obs")
if noncentred:
mu_beta, sigma_beta = priors["beta_"]
beta_std = pm.Normal("beta_std", 0, 1, dims="betas")
beta = pm.Deterministic(
"beta_", mu_beta + sigma_beta * beta_std, dims="betas"
)
else:
beta = pm.Normal(
"beta_", priors["beta_"][0], priors["beta_"][1], dims="betas"
)
alpha_outcome = pm.Normal(
"alpha_outcome", priors["alpha_outcome"][0], priors["alpha_outcome"][1]
)
mu_outcome = alpha_outcome + pm.math.dot(X_data_outcome, beta)
sigma = pm.HalfNormal("sigma", priors["sigma"])
_ = pm.Normal("like", mu_outcome, sigma, observed=Y_data_, dims="obs")
idata = pm.sample(**sampler_kwargs)
return reg_model, idata
Putting it all Together#
We are now in a position to fit both joint and modular (2-stage) models to our simulated data. We are seeking to assess how the different approaches to incorporating propensity score information impacts the accuracy of the treatment effect estimate.
Note
We are using this snippet of code to pass the posterior distribution of the propensity score through to the outcome model and have it be sampled in the MCMC process of the outcome model.
chosen = np.random.choice(range(propensity_scores.shape[1]))
p = propensity_scores[:, chosen].values
This allows us to modularise the the fitting process but retain the useful information stored in the propensity score.
priors = {
"beta_": [0, 3],
"beta_trt": [0, 1],
"alpha_trt": [0, 1],
"alpha_outcome": [0, 1],
"sigma": 1,
"beta_ps": [0, 1],
}
joint_model = make_joint_model(X_trt, X_outcome, T_data, Y_data, coords, priors=priors)
with joint_model:
idata_joint = pm.sample(**sampler_kwargs)
(
idata_treatment_2s_joint,
idata_outcome_2s_joint,
treatment_model_joint,
outcome_model_joint,
) = make_2step_model(
X_trt, X_outcome, T_data, Y_data, coords, priors, spline_component=False
)
(
idata_treatment_2s_joint_spline,
idata_outcome_2s_joint_spline,
treatment_model_joint_spline,
outcome_model_joint_spline,
) = make_2step_model(
X_trt, X_outcome, T_data, Y_data, coords, priors, spline_component=True
)
reg_model, idata_outcome_simple_reg = make_reg_model(X_outcome, Y_data, coords)
Show code cell output
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_trt_std, beta_std, beta_ps, alpha_trt, alpha_outcome, sigma]
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 80 seconds.
Sampling: [alpha_trt, beta_trt_std, t_pred]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_trt_std, alpha_trt]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 20 seconds.
Sampling: [alpha_outcome, beta_ps, beta_std, like, sigma]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_std, beta_ps, alpha_outcome, sigma]
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 16 seconds.
Sampling: [alpha_trt, beta_trt_std, t_pred]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_trt_std, alpha_trt]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 18 seconds.
Sampling: [alpha_outcome, beta_ps, beta_ps_spline, beta_std, like, sigma]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_std, beta_ps, alpha_outcome, beta_ps_spline, sigma]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 37 seconds.
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_std, alpha_outcome, sigma]
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 12 seconds.
ax = az.plot_forest(
[
idata_outcome_2s_joint,
idata_outcome_2s_joint_spline,
idata_joint,
idata_outcome_simple_reg,
],
var_names=["beta_"],
model_names=["2 Stage", "2 Stage + Spline", "1 Stage", "Simple Regression"],
combined=True,
figsize=(10, 5),
)
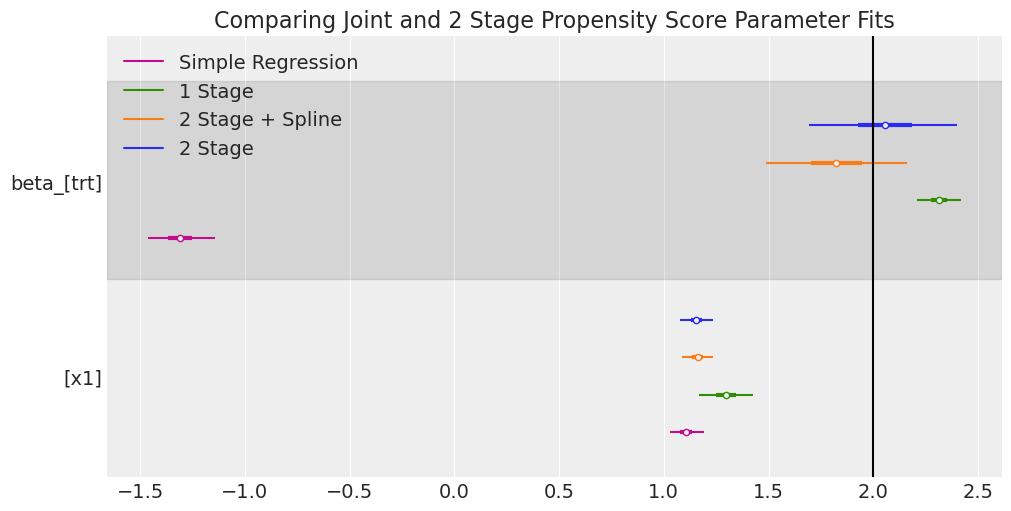
ax[0].axvline(2, label="True Treatment Value", color="k")
ax[0].set_title("Comparing Joint and 2 Stage Propensity Score Parameter Fits");
Show code cell source
compare_estimate = pd.concat(
{
"1-stage-model": az.summary(
idata_joint, var_names=["alpha_trt", "beta_", "beta_ps", "alpha_outcome"]
),
"2-stage-model": az.summary(
idata_outcome_2s_joint, var_names=["beta_", "alpha_outcome", "beta_ps"]
),
"2-stage-model_spline": az.summary(
idata_outcome_2s_joint_spline,
var_names=["beta_", "alpha_outcome", "beta_ps"],
),
"Simple Regression": az.summary(
idata_outcome_simple_reg,
var_names=["beta_", "alpha_outcome"],
),
}
)
compare_estimate[["mean", "sd", "hdi_3%", "hdi_97%", "r_hat"]]
| mean | sd | hdi_3% | hdi_97% | r_hat | ||
|---|---|---|---|---|---|---|
| 1-stage-model | alpha_trt | 0.000 | 0.021 | -0.040 | 0.041 | 1.0 |
| beta_[trt] | 2.314 | 0.057 | 2.206 | 2.419 | 1.0 | |
| beta_[x1] | 1.296 | 0.070 | 1.167 | 1.428 | 1.0 | |
| beta_ps | -15.297 | 0.294 | -15.840 | -14.738 | 1.0 | |
| alpha_outcome | 8.507 | 0.161 | 8.216 | 8.821 | 1.0 | |
| 2-stage-model | beta_[trt] | 2.058 | 0.189 | 1.696 | 2.398 | 1.0 |
| beta_[x1] | 1.155 | 0.041 | 1.079 | 1.235 | 1.0 | |
| alpha_outcome | 3.067 | 0.060 | 2.953 | 3.176 | 1.0 | |
| beta_ps | -4.147 | 0.210 | -4.541 | -3.759 | 1.0 | |
| 2-stage-model_spline | beta_[trt] | 1.824 | 0.179 | 1.490 | 2.161 | 1.0 |
| beta_[x1] | 1.162 | 0.040 | 1.087 | 1.236 | 1.0 | |
| alpha_outcome | 1.007 | 0.293 | 0.441 | 1.544 | 1.0 | |
| beta_ps | -0.009 | 0.983 | -1.797 | 1.880 | 1.0 | |
| Simple Regression | beta_[trt] | -1.308 | 0.085 | -1.464 | -1.144 | 1.0 |
| beta_[x1] | 1.107 | 0.043 | 1.029 | 1.190 | 1.0 | |
| alpha_outcome | 2.665 | 0.060 | 2.549 | 2.773 | 1.0 |
Here the models fail to recover substantially similar and correct results, in particular the simple regression model is widely off. However the 2-stage models seem to perform better than the joint model specification. This is interesting and demonstrates a key property of propensity scores in the Bayesian setting. Propensity scores are useful correctives within a regression context but we need to be careful how the model is specified.
The Problem of Feedback#
The issue here is sometimes called Bayesian feedback or “collider bias via the likelihood” [Griffith et al., 2020], and it’s a key issue when trying to build joint models for causal inference in the Bayesian paradigm. Because we have fit the outcome and the treatment models simultaneously, and this means that the outcome can influence the posterior distribution of the parameters \(\beta\) in the treatment model and it violates the idea of design-before-analysis. We have here an apparent example of a slight bias due to this effect. The two stage modular approach seems to better recover the treatment effect reported in the literature and avoids the risk of collider bias i.e. in the modular implementation we are able to use the propensity score to adjust for accuracy and compensate for the missing variables x2 and x1.
💡 Key Take-away: With an underspecified outcome model, we may use a well specified propensity score for adjusting the model to retrieve accurate treatment effect estimates. However, this tends to breakdown if we have estimated both propensity score and outcome in a joint bayesian model due to feedback effects. The solution is to use the propensity score in a 2 stage fashion.
pm.model_to_graphviz(outcome_model_joint_spline)

Propensity Score Quantiles - Joint Model#
We can see how the different model specifications have yielded distinct propensity score estimates - as the joint specification seems to compensate for missing covariates in the outcome model by adjusting the propensity score latent in the treatment model too. We can see the differences in the quantiles to highlight a numeric difference in the propensity score distributions between the two models.
idata_joint["posterior"]["p"].quantile(
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
).round(3).values
array([0.224, 0.308, 0.38 , 0.442, 0.502, 0.563, 0.624, 0.691, 0.769])
Propensity Score Quantiles - 2 Stage Modular Model#
The range an position of these quantiles is vastly different than the joint model specification.
idata_treatment_2s_joint["posterior"]["p"].quantile(
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
).round(3).values
array([0. , 0.001, 0.014, 0.11 , 0.506, 0.886, 0.986, 0.999, 1. ])
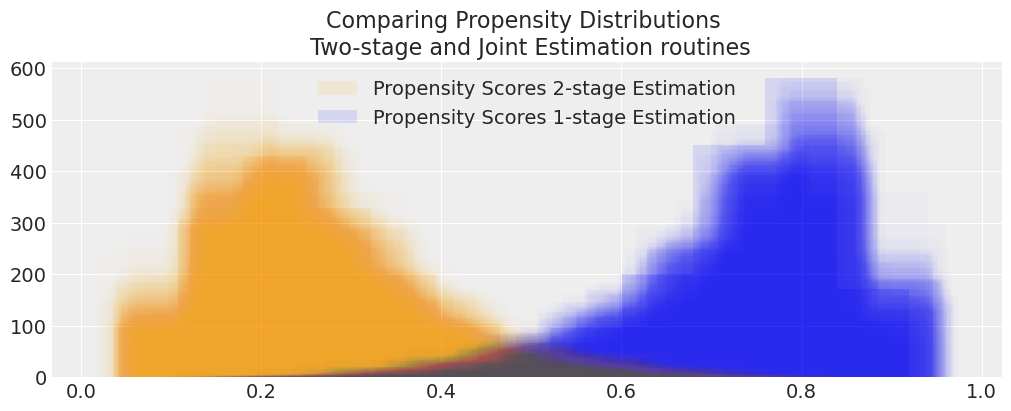
Comparing Propensity Score Skew#
We have seen how the treatment effect reported by both models differ and that the joint model exhibits a bias away from the true treatment effect. But we might want to see how this bias manifests in the propensity score distribution.
def compare_propensity_dists(idata_2s, idata_1s):
fig, ax = plt.subplots(figsize=(10, 4))
for i in range(100):
s2 = idata_2s["posterior"].stack(z=("chain", "draw"))["p"][:, i]
s1 = idata_1s["posterior"].stack(z=("chain", "draw"))["p"][:, i]
if i == 0:
ax.hist(
s2,
alpha=0.1,
color="orange",
label="Propensity Scores 2-stage Estimation",
)
# Pivoted to compare shape
ax.hist(
1 - s1,
alpha=0.1,
color="blue",
label="Propensity Scores 1-stage Estimation",
)
else:
ax.hist(s2, alpha=0.01, color="orange")
# Pivoted to compare shape
ax.hist(1 - s1, alpha=0.01, color="blue")
ax.legend()
ax.set_title(
"Comparing Propensity Distributions \n Two-stage and Joint Estimation routines"
)
compare_propensity_dists(idata_treatment_2s_joint, idata_joint)
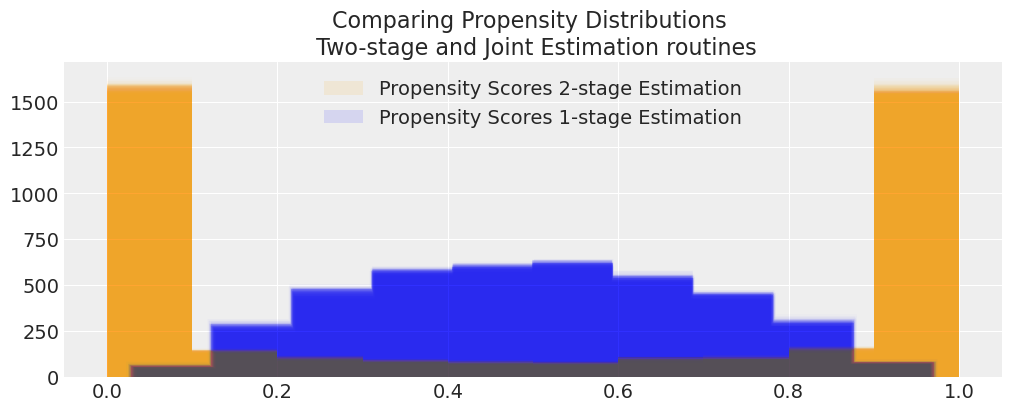
These are radically different models due to the feedback mechanism. How does this phenomena play out in some real world examples?
spline_features = az.extract(idata_outcome_2s_joint_spline)["spline_features"]
propensity_scores = az.extract(idata_treatment_2s_joint_spline)["p"]
fig, ax = plt.subplots(figsize=(10, 5))
for i in range(100):
temp = pd.DataFrame(
{"prop_score": propensity_scores[:, i], "spline": spline_features[:, i]}
)
temp.sort_values("prop_score", inplace=True)
ax.plot(temp["prop_score"], temp["spline"], alpha=0.01, color="blue")
temp = pd.DataFrame(
{
"prop_score": propensity_scores.mean(axis=1),
"spline": spline_features.mean(axis=1),
}
)
temp.sort_values("prop_score", inplace=True)
ax.plot(temp["prop_score"], temp["spline"], color="k", label="Expected Value")
ax.set_title("Additive Spline Effect on the Propensity Score")
ax.legend()
ax.set_ylabel("Spline Feature Contribution")
ax.set_xlabel("Propensity Score");
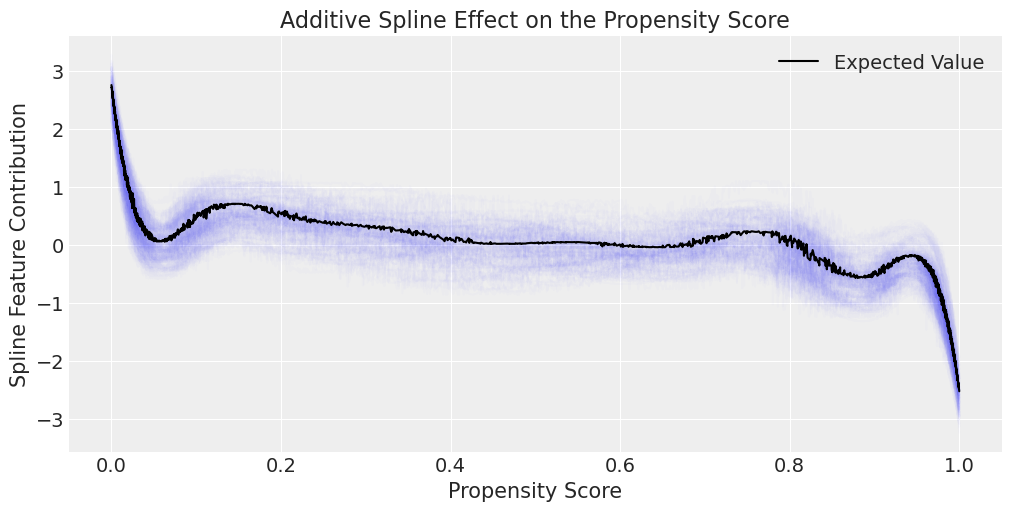
Note
The idea of allowing a spline component to contribute to the mu_outcome or expectation of our model, is that in some cases there might be a non-linear relationship between the propensity for treatment and the outcome interest.
Incorporating the spline function of p grants our model this kind of flexibility to account for different response categories across levels of the propensity score.
Causal Estimate with Do-Operator#
We can also confirm the model implications through counterfactual imputation. This ties the Bayesian setting back to the potential outcome framework. The fundamental problem of causal inference, when seen as a missing data problem allows us to derive causal estimands through imputation of the potential outcomes. Here we “push forward” the posterior predictive distribution for \(Y\) under different treatment settings.
X_outcome_trt = X_outcome.copy()
X_outcome_trt[:, 0] = 1
X_outcome_ntrt = X_outcome.copy()
X_outcome_ntrt[:, 0] = 0
First we specify our counterfactual input data. Then we push them through the joint model distribution using the do-operator in PyMC to sample from the posterior predictive distribution giving us sample of the potential outcomes \(Y(1), Y(0)\)
with pm.do(
joint_model,
{"T": np.ones(len(df1), dtype=np.int32), "X_outcome": X_outcome_trt},
prune_vars=True,
) as treatment_model:
idata_trt = pm.sample_posterior_predictive(idata_joint, var_names=["like", "p"])
with pm.do(
joint_model,
{"T": np.zeros(len(df1), dtype=np.int32), "X_outcome": X_outcome_ntrt},
prune_vars=True,
) as ntreatment_model:
idata_ntrt = pm.sample_posterior_predictive(idata_joint, var_names=["like", "p"])
Sampling: [like]
Sampling: [like]
For sake of illustration we calculate the mean value for \(Y(1)\)
idata_trt["posterior_predictive"]["like"].mean().item()
3.1565468847153166
The mean value for \(Y(0)\)
idata_ntrt["posterior_predictive"]["like"].mean().item()
0.8421930047703092
and their difference, which is the causal estimand of interest.
(
idata_trt["posterior_predictive"]["like"].mean().item()
- idata_ntrt["posterior_predictive"]["like"].mean().item()
)
2.314353879945007
In this way we can impute potential outcomes gain insight into any variety of causal estimands we care to calculate. In this case, we have re-derived the insight that the joint model yields a biased treatment effect estimate.
Nets Example#
Next we’ll asses a data set used by Andrew Heiss to demonstrate propensity score methods with brms.
nets_df = cp.load_data("nets")
nets_df["trt"] = nets_df["net_num"]
nets_df["outcome"] = nets_df["malaria_risk"]
nets_df.head()
| id | net | net_num | malaria_risk | income | health | household | eligible | temperature | resistance | trt | outcome | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | True | 1 | 33 | 781 | 56 | 2 | False | 21.1 | 59 | 1 | 33 |
| 1 | 2 | False | 0 | 42 | 974 | 57 | 4 | False | 26.5 | 73 | 0 | 42 |
| 2 | 3 | False | 0 | 80 | 502 | 15 | 3 | False | 25.6 | 65 | 0 | 80 |
| 3 | 4 | True | 1 | 34 | 671 | 20 | 5 | True | 21.3 | 46 | 1 | 34 |
| 4 | 5 | False | 0 | 44 | 728 | 17 | 5 | False | 19.2 | 54 | 0 | 44 |
coords = {
"betas": ["trt", "income"],
"betas_trt": ["income", "temperature", "health"],
"obs": range(nets_df.shape[0]),
}
# Process and Standardise Inputs
N = nets_df.shape[0]
X_trt = nets_df[["income", "temperature", "health"]].values
X_trt = (X_trt - X_trt.mean(axis=0)) / X_trt.std(axis=0)
X_outcome = nets_df[["trt", "income"]].values
X_outcome = (X_outcome - X_outcome.mean(axis=0)) / X_outcome.std(axis=0)
T_data = nets_df["trt"].values
X_outcome[:, 0] = T_data
Y_data = nets_df["outcome"].values
priors = {
"beta_": [0, 1],
"beta_trt": [0, 1],
"alpha_trt": [0, 1],
"alpha_outcome": [40, 30],
"sigma": 15,
"beta_ps": [0, 1],
}
net_model = make_joint_model(
X_trt, X_outcome, T_data, Y_data, coords, priors=priors, normal_outcome=False
)
with net_model:
idata_net = pm.sample(tune=2000, target_accept=0.98)
idata_treatment_2s_net, idata_outcome_2s_net, treatment_model_net, outcome_model_net = (
make_2step_model(
X_trt, X_outcome, T_data, Y_data, coords, priors=priors, normal_outcome=False
)
)
reg_model_nets, idata_outcome_simple_reg_nets = make_reg_model(
X_outcome, Y_data, coords
)
Show code cell output
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_trt_std, beta_std, beta_ps, alpha_trt, alpha_outcome, sigma, nu]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 17 seconds.
Sampling: [alpha_trt, beta_trt_std, t_pred]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_trt_std, alpha_trt]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 14 seconds.
Sampling: [alpha_outcome, beta_ps, beta_std, like, nu, sigma]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_std, beta_ps, alpha_outcome, sigma, nu]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 15 seconds.
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_std, alpha_outcome, sigma]
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 11 seconds.
ax = az.plot_forest(
[idata_outcome_2s_net, idata_net, idata_outcome_simple_reg_nets],
var_names=["beta_"],
model_names=["2 Stage", "1 Stage", "Simple Regression"],
combined=True,
figsize=(10, 4),
)
ax[0].axvline(-10, label="True Treatment Value", color="k")
ax[0].set_title("Comparing Joint and 2 Stage Propensity Score Parameter Fits");
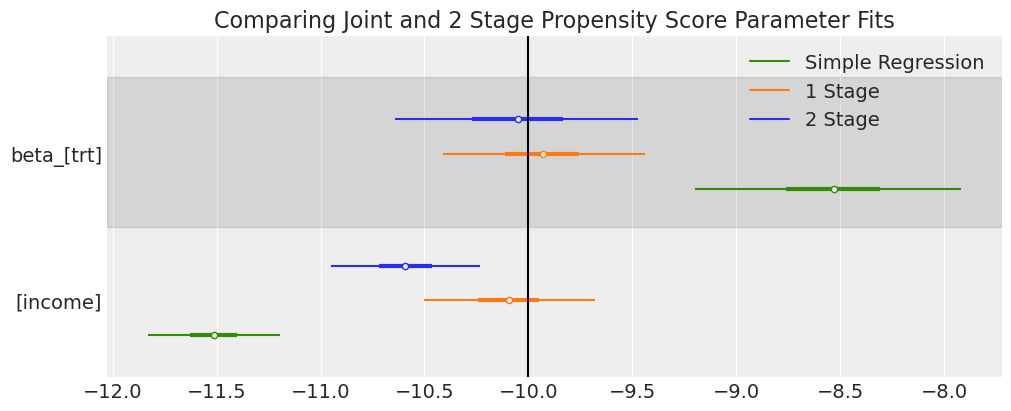
As before we have used both model specifications to derive estimates for the treatment effect. In this case we have allowed the outcome model access to only a single income predictor. And while both models seem to approximtely recover the reported -10 treatment estimate with a large degree of uncertainty. The modular 2 stage estimates pulls away from the joint model estimate.
Show code cell source
compare_estimate = pd.concat(
{
"1-stage-model": az.summary(
idata_net,
var_names=["alpha_trt", "beta_", "beta_ps", "alpha_outcome"],
),
"2-stage-model": az.summary(
idata_outcome_2s_net, var_names=["beta_", "alpha_outcome", "beta_ps"]
),
"Simple Regression": az.summary(
idata_outcome_simple_reg_nets, var_names=["beta_", "alpha_outcome"]
),
}
)
compare_estimate[["mean", "sd", "hdi_3%", "hdi_97%", "r_hat"]]
| mean | sd | hdi_3% | hdi_97% | r_hat | ||
|---|---|---|---|---|---|---|
| 1-stage-model | alpha_trt | -0.261 | 0.052 | -0.358 | -0.165 | 1.0 |
| beta_[trt] | -9.933 | 0.262 | -10.410 | -9.440 | 1.0 | |
| beta_[income] | -10.097 | 0.221 | -10.503 | -9.680 | 1.0 | |
| beta_ps | -16.194 | 0.654 | -17.454 | -15.004 | 1.0 | |
| alpha_outcome | 46.580 | 0.397 | 45.841 | 47.317 | 1.0 | |
| 2-stage-model | beta_[trt] | -10.053 | 0.316 | -10.640 | -9.475 | 1.0 |
| beta_[income] | -10.593 | 0.192 | -10.947 | -10.232 | 1.0 | |
| alpha_outcome | 42.202 | 0.415 | 41.418 | 42.976 | 1.0 | |
| beta_ps | -7.146 | 0.938 | -8.913 | -5.427 | 1.0 | |
| Simple Regression | beta_[trt] | -8.534 | 0.338 | -9.198 | -7.920 | 1.0 |
| beta_[income] | -11.515 | 0.169 | -11.831 | -11.193 | 1.0 | |
| alpha_outcome | 37.832 | 0.216 | 37.439 | 38.255 | 1.0 |
This kind of difference need not be very concerning but we should check if the bias stems from a difference in latent propensity scores as before.
idata_net["posterior"]["p"].quantile(
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
).round(3).values
array([0.181, 0.249, 0.31 , 0.369, 0.43 , 0.5 , 0.571, 0.643, 0.727])
The quantiles of the propensity distributions across both models seem different.
idata_treatment_2s_net["posterior"]["p"].quantile(
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
).round(3).values
array([0.239, 0.283, 0.317, 0.349, 0.379, 0.412, 0.449, 0.492, 0.556])
compare_propensity_dists(idata_treatment_2s_net, idata_net)
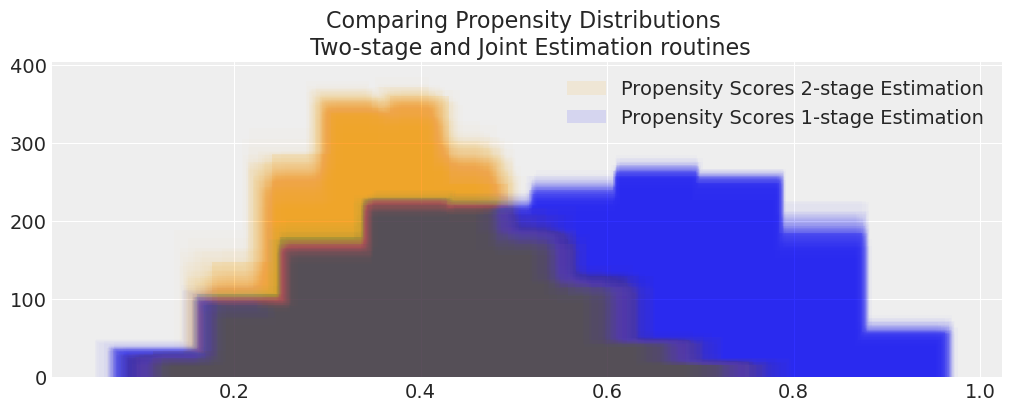
Here we see some divergence between the propensity score estimates indicating that the regression adjustment approach in the 2 stage outcome model is correcting for bias in the joint-distribution. However both credible intervals contain the reported treatment effect of -10 so the skew is perhaps less concerning. This is despite the fact that we removed useful predictors temperature, health from the outcome model specification. The model leans on the information contained in the propensity score and weights the beta_ps information appropriately.
LaLonde Example#
The Lalonde Data set is famous because it highlights a problem with naive causal contrasts. It is discussed by Angrist and Pischke in their Mostly Harmless Econometrics as an example of how regression controls can tolerably address selection effects in a way similar to propensity score weighting. So we should hope the a well specified outcome model can identify the treatment effects plausibly here too.
lalonde = df = cp.load_data("lalonde")
lalonde[["hispan", "white"]] = pd.get_dummies(lalonde["race"], drop_first=True)
lalonde.dropna(inplace=True)
lalonde.head()
| rownames | treat | age | educ | race | married | nodegree | re74 | re75 | re78 | hispan | white | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NSW1 | 1 | 37 | 11 | black | 1 | 1 | 0.0 | 0.0 | 9930.0460 | False | False |
| 1 | NSW2 | 1 | 22 | 9 | hispan | 0 | 1 | 0.0 | 0.0 | 3595.8940 | True | False |
| 2 | NSW3 | 1 | 30 | 12 | black | 0 | 0 | 0.0 | 0.0 | 24909.4500 | False | False |
| 3 | NSW4 | 1 | 27 | 11 | black | 0 | 1 | 0.0 | 0.0 | 7506.1460 | False | False |
| 4 | NSW5 | 1 | 33 | 8 | black | 0 | 1 | 0.0 | 0.0 | 289.7899 | False | False |
lalonde.groupby("treat")["re78"].mean().diff()
treat
0 NaN
1 -635.026212
Name: re78, dtype: float64
The Naive group difference suggests a negative effect. Lets see how our two models work when we remove predictors from the propensity model?
coords = {
"betas": ["treat", "nodegree", "married"],
"betas_trt": ["age", "educ", "hispan", "white", "married", "nodegree"],
"obs": range(lalonde.shape[0]),
}
N = lalonde.shape[0]
X_trt = (
lalonde[["age", "educ", "hispan", "white", "married", "nodegree"]]
.astype(np.int32)
.values
)
X_trt = (X_trt - X_trt.mean(axis=0)) / X_trt.std(axis=0)
X_outcome = lalonde[["treat", "nodegree", "married"]].astype(np.int32).values
# X_outcome = (X_outcome - X_outcome.mean()) / X_outcome.std()
T_data = lalonde["treat"].values
Y_data = lalonde["re78"].values
priors = {
"beta_": [0, 4000],
"beta_trt": [0, 1],
"alpha_trt": [0, 1],
"alpha_outcome": [2000, 500],
"sigma": 500,
"beta_ps": [0, 30],
}
lalonde_model = make_joint_model(
X_trt, X_outcome, T_data, Y_data, coords, priors, noncentred=False
)
with lalonde_model:
idata_lalonde = pm.sample(tune=5000)
(
idata_treatment_2s_lalonde,
idata_outcome_2s_lalonde,
treatment_model_lalonde,
outcome_model_lalonde,
) = make_2step_model(
X_trt,
X_outcome,
T_data,
Y_data,
coords,
priors=priors,
spline_component=True,
winsorize_boundary=0.1,
)
reg_model_lalonde, idata_outcome_simple_reg_lalonde = make_reg_model(
X_outcome, Y_data, coords, priors=priors
)
Show code cell output
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_trt_, beta_, beta_ps, alpha_trt, alpha_outcome, sigma]
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)
Sampling 4 chains for 5_000 tune and 1_000 draw iterations (20_000 + 4_000 draws total) took 6 seconds.
Sampling: [alpha_trt, beta_trt_std, t_pred]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_trt_std, alpha_trt]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 13 seconds.
Sampling: [alpha_outcome, beta_ps, beta_ps_spline, beta_std, like, sigma]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_std, beta_ps, alpha_outcome, beta_ps_spline, sigma]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 14 seconds.
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_std, alpha_outcome, sigma]
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 11 seconds.
ax = az.plot_forest(
[idata_outcome_2s_lalonde, idata_lalonde, idata_outcome_simple_reg_lalonde],
var_names=["beta_", "sigma"],
model_names=["2 Stage", "1 Stage", "Simple Regression"],
combined=True,
figsize=(10, 4),
)
# Experimental benchmark between 1600 - 1800
ax[0].axvline(1700, color="black")
ax[0].set_title("Comparing Joint and 2 Stage Propensity Score Parameter Fits");
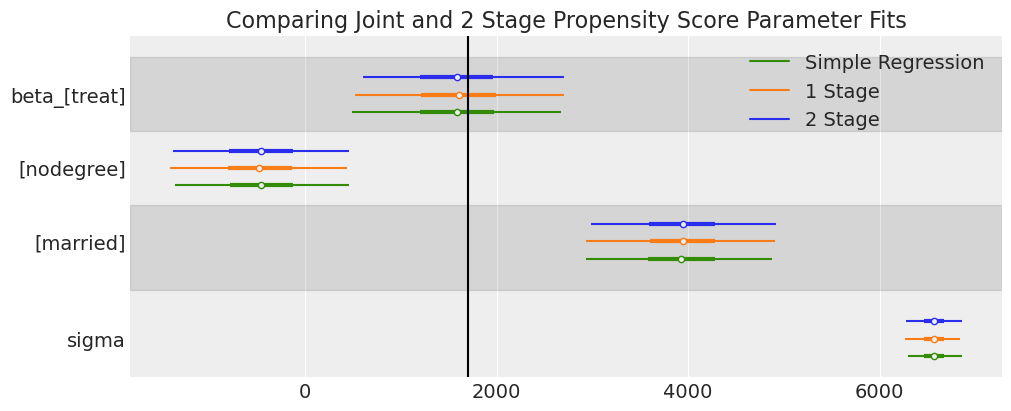
Show code cell source
compare_estimate = pd.concat(
{
"1-stage-model": az.summary(
idata_lalonde,
var_names=["alpha_trt", "beta_", "beta_ps", "alpha_outcome", "sigma"],
),
"2-stage-model": az.summary(
idata_outcome_2s_lalonde,
var_names=["beta_", "beta_ps", "alpha_outcome", "sigma"],
),
"Simple Regression": az.summary(
idata_outcome_simple_reg_lalonde,
var_names=["beta_", "alpha_outcome", "sigma"],
),
}
)
compare_estimate[["mean", "sd", "hdi_3%", "hdi_97%", "r_hat"]]
| mean | sd | hdi_3% | hdi_97% | r_hat | ||
|---|---|---|---|---|---|---|
| 1-stage-model | alpha_trt | -1.360 | 0.136 | -1.607 | -1.096 | 1.0 |
| beta_[treat] | 1596.367 | 592.252 | 522.004 | 2698.841 | 1.0 | |
| beta_[nodegree] | -478.468 | 494.181 | -1411.118 | 431.650 | 1.0 | |
| beta_[married] | 3941.883 | 521.193 | 2935.781 | 4905.149 | 1.0 | |
| beta_ps | 1.515 | 30.782 | -59.159 | 56.783 | 1.0 | |
| alpha_outcome | 4318.250 | 369.288 | 3624.124 | 5022.575 | 1.0 | |
| sigma | 6567.379 | 152.789 | 6262.905 | 6837.376 | 1.0 | |
| 2-stage-model | beta_[treat] | 1588.023 | 560.154 | 606.842 | 2705.402 | 1.0 |
| beta_[nodegree] | -459.243 | 493.565 | -1378.890 | 456.611 | 1.0 | |
| beta_[married] | 3938.877 | 513.101 | 2988.612 | 4920.545 | 1.0 | |
| beta_ps | -0.041 | 29.752 | -56.003 | 56.809 | 1.0 | |
| alpha_outcome | 4311.600 | 368.082 | 3627.173 | 5011.784 | 1.0 | |
| sigma | 6569.193 | 153.745 | 6279.593 | 6855.407 | 1.0 | |
| Simple Regression | beta_[treat] | 1582.104 | 582.999 | 493.442 | 2672.645 | 1.0 |
| beta_[nodegree] | -454.568 | 492.429 | -1360.717 | 461.760 | 1.0 | |
| beta_[married] | 3926.351 | 519.744 | 2930.813 | 4873.111 | 1.0 | |
| alpha_outcome | 4320.328 | 368.753 | 3628.037 | 4996.010 | 1.0 | |
| sigma | 6568.130 | 149.699 | 6293.193 | 6860.301 | 1.0 |
The model estimates are basically identical. We should expect mirrored propensity score distributions indicating that feedback wasn’t an issue. The outcome model leaned primarily on the covariate profile \(X\) to derive the treatment effect estimate.
compare_propensity_dists(idata_treatment_2s_lalonde, idata_lalonde)
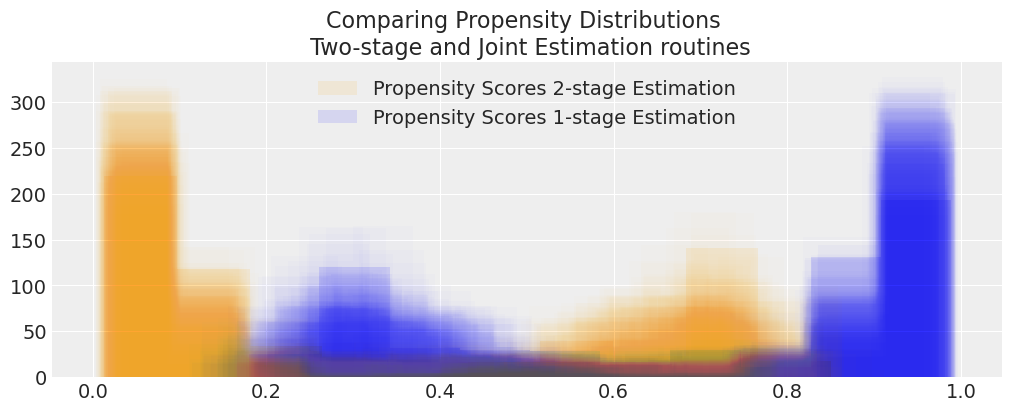
Both estimates of the treatment effects accord well with values in the literature. We can be happy that both models are picking up on the treatment effects reasonably well, despite having a minimalist outcome model. This is because in the Bayesian setting the conditional distribution of \(X, T\) are generally sufficient when there is no unmeasured confounders. Here the model somewhat ignores the propensity score coefficients beta_ps.
NHEFS#
Finally we turn to the NHEFS data as discussed by Hernan in [Hernan, 2024]. This data is known to be have a complex covariate profile for measuring aspects smokers health. We might suspect that there is some unmeasured confounding in this data set that would be hard to pick up on with simple regression controls.
df = cp.load_data("nhefs")
df[["age", "race", "trt", "smokeintensity", "smokeyrs", "outcome"]].head()
| age | race | trt | smokeintensity | smokeyrs | outcome | |
|---|---|---|---|---|---|---|
| 0 | 42 | 1 | 0 | 30 | 29 | -10.093960 |
| 1 | 36 | 0 | 0 | 20 | 24 | 2.604970 |
| 2 | 56 | 1 | 0 | 20 | 26 | 9.414486 |
| 3 | 68 | 1 | 0 | 3 | 53 | 4.990117 |
| 4 | 40 | 0 | 0 | 20 | 19 | 4.989251 |
coords = {
"betas": ["trt", "age", "race", "sex", "smokeintensity", "smokeyrs", "wt71"],
"betas_trt": [
"age",
"race",
"sex",
"smokeintensity",
"smokeyrs",
"wt71",
"active_1",
"active_2",
"education_2",
"education_3",
"education_4",
"education_5",
"exercise_1",
"exercise_2",
"age^2",
"wt71^2",
"smokeintensity^2",
"smokeyrs^2",
],
"obs": range(df.shape[0]),
}
N = df.shape[0]
X_trt = df[
[
"age",
"race",
"sex",
"smokeintensity",
"smokeyrs",
"wt71",
"active_1",
"active_2",
"education_2",
"education_3",
"education_4",
"education_5",
"exercise_1",
"exercise_2",
"age^2",
"wt71^2",
"smokeintensity^2",
"smokeyrs^2",
]
]
X_trt = (X_trt - X_trt.mean(axis=0)) / X_trt.std(axis=0)
# Note the significantly reduced outcome model specification.
X_outcome = df[["trt", "age", "race", "sex", "smokeintensity", "smokeyrs", "wt71"]]
X_outcome = (X_outcome - X_outcome.mean(axis=0)) / X_outcome.std(axis=0)
T_data = df["trt"].values
X_outcome["trt"] = T_data
Y_data = df["outcome"].values
priors = {
"beta_": [0, 3],
"beta_trt": [0, 1],
"alpha_trt": [0, 1],
"alpha_outcome": [0, 5],
"sigma": 10,
"beta_ps": [0, 10],
}
nhefs_model = make_joint_model(X_trt, X_outcome, T_data, Y_data, coords, priors)
with nhefs_model:
idata_nhefs = pm.sample(**sampler_kwargs)
(
idata_treatment_2s_nhefs,
idata_outcome_2s_nhefs,
treatment_model_nhefs,
outcome_model_nhefs,
) = make_2step_model(
X_trt,
X_outcome,
T_data,
Y_data,
coords,
priors=priors,
spline_component=True,
)
reg_model_nhefs, idata_outcome_simple_reg_nhefs = make_reg_model(
X_outcome, Y_data, coords, priors=priors
)
Show code cell output
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_trt_std, beta_std, beta_ps, alpha_trt, alpha_outcome, sigma]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 56 seconds.
Sampling: [alpha_trt, beta_trt_std, t_pred]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_trt_std, alpha_trt]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 40 seconds.
Sampling: [alpha_outcome, beta_ps, beta_ps_spline, beta_std, like, sigma]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_std, beta_ps, alpha_outcome, beta_ps_spline, sigma]
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 29 seconds.
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_std, alpha_outcome, sigma]
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 13 seconds.
ax = az.plot_forest(
[idata_outcome_2s_nhefs, idata_nhefs, idata_outcome_simple_reg_nhefs],
var_names=["beta_"],
model_names=["2 Stage", "1 Stage", "Simple Regression"],
combined=True,
figsize=(10, 4),
)
ax[0].axvline(3.4, label="True Treatment Value", color="k")
ax[0].set_title("Comparing Joint and 2 Stage Propensity Score Parameter Fits");
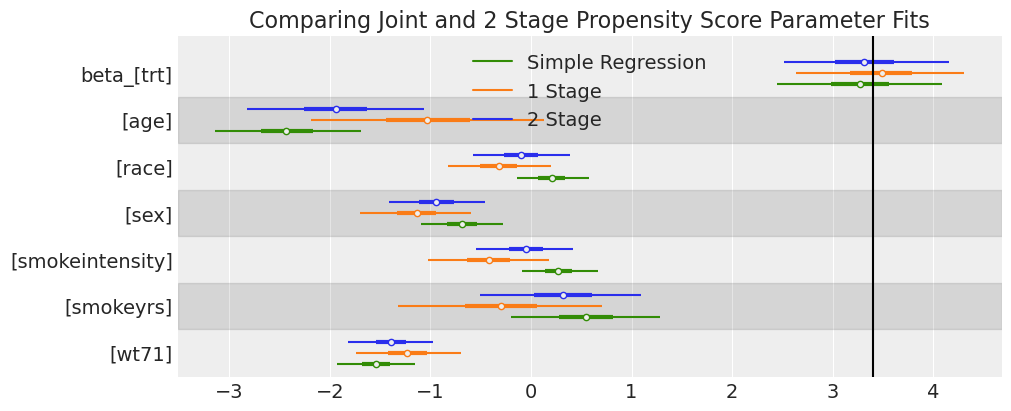
Here we see the model specifications start to come apart slightly, although the effect of feedback seems to primarily influence the impact of age on the outcome rather than the treatment estimate.
Show code cell source
compare_estimate = pd.concat(
{
"1-stage-model": az.summary(
idata_nhefs, var_names=["alpha_trt", "beta_", "alpha_outcome", "beta_ps"]
),
"2-stage-model": az.summary(
idata_outcome_2s_nhefs, var_names=["beta_", "alpha_outcome", "beta_ps"]
),
"Simple Regression": az.summary(
idata_outcome_simple_reg_nhefs, var_names=["beta_", "alpha_outcome"]
),
}
)
compare_estimate[["mean", "sd", "hdi_3%", "hdi_97%", "r_hat"]]
| mean | sd | hdi_3% | hdi_97% | r_hat | ||
|---|---|---|---|---|---|---|
| 1-stage-model | alpha_trt | -1.146 | 0.061 | -1.262 | -1.034 | 1.0 |
| beta_[trt] | 3.487 | 0.445 | 2.637 | 4.310 | 1.0 | |
| beta_[age] | -1.018 | 0.620 | -2.187 | 0.128 | 1.0 | |
| beta_[race] | -0.323 | 0.273 | -0.822 | 0.195 | 1.0 | |
| beta_[sex] | -1.145 | 0.295 | -1.706 | -0.599 | 1.0 | |
| beta_[smokeintensity] | -0.431 | 0.319 | -1.024 | 0.175 | 1.0 | |
| beta_[smokeyrs] | -0.303 | 0.540 | -1.318 | 0.702 | 1.0 | |
| beta_[wt71] | -1.221 | 0.281 | -1.742 | -0.698 | 1.0 | |
| alpha_outcome | 5.204 | 1.002 | 3.223 | 7.004 | 1.0 | |
| beta_ps | -13.476 | 3.820 | -20.775 | -6.420 | 1.0 | |
| 2-stage-model | beta_[trt] | 3.319 | 0.435 | 2.517 | 4.155 | 1.0 |
| beta_[age] | -1.937 | 0.469 | -2.824 | -1.068 | 1.0 | |
| beta_[race] | -0.101 | 0.257 | -0.575 | 0.392 | 1.0 | |
| beta_[sex] | -0.940 | 0.255 | -1.409 | -0.454 | 1.0 | |
| beta_[smokeintensity] | -0.052 | 0.255 | -0.542 | 0.420 | 1.0 | |
| beta_[smokeyrs] | 0.317 | 0.424 | -0.510 | 1.094 | 1.0 | |
| beta_[wt71] | -1.393 | 0.222 | -1.818 | -0.980 | 1.0 | |
| alpha_outcome | 1.363 | 2.904 | -4.256 | 6.557 | 1.0 | |
| beta_ps | -0.023 | 10.048 | -18.154 | 19.192 | 1.0 | |
| Simple Regression | beta_[trt] | 3.270 | 0.435 | 2.450 | 4.087 | 1.0 |
| beta_[age] | -2.427 | 0.387 | -3.142 | -1.688 | 1.0 | |
| beta_[race] | 0.204 | 0.193 | -0.141 | 0.577 | 1.0 | |
| beta_[sex] | -0.685 | 0.218 | -1.096 | -0.278 | 1.0 | |
| beta_[smokeintensity] | 0.270 | 0.199 | -0.088 | 0.666 | 1.0 | |
| beta_[smokeyrs] | 0.547 | 0.393 | -0.203 | 1.286 | 1.0 | |
| beta_[wt71] | -1.543 | 0.208 | -1.932 | -1.151 | 1.0 | |
| alpha_outcome | 1.795 | 0.216 | 1.371 | 2.184 | 1.0 |
compare_propensity_dists(idata_treatment_2s_nhefs, idata_nhefs)
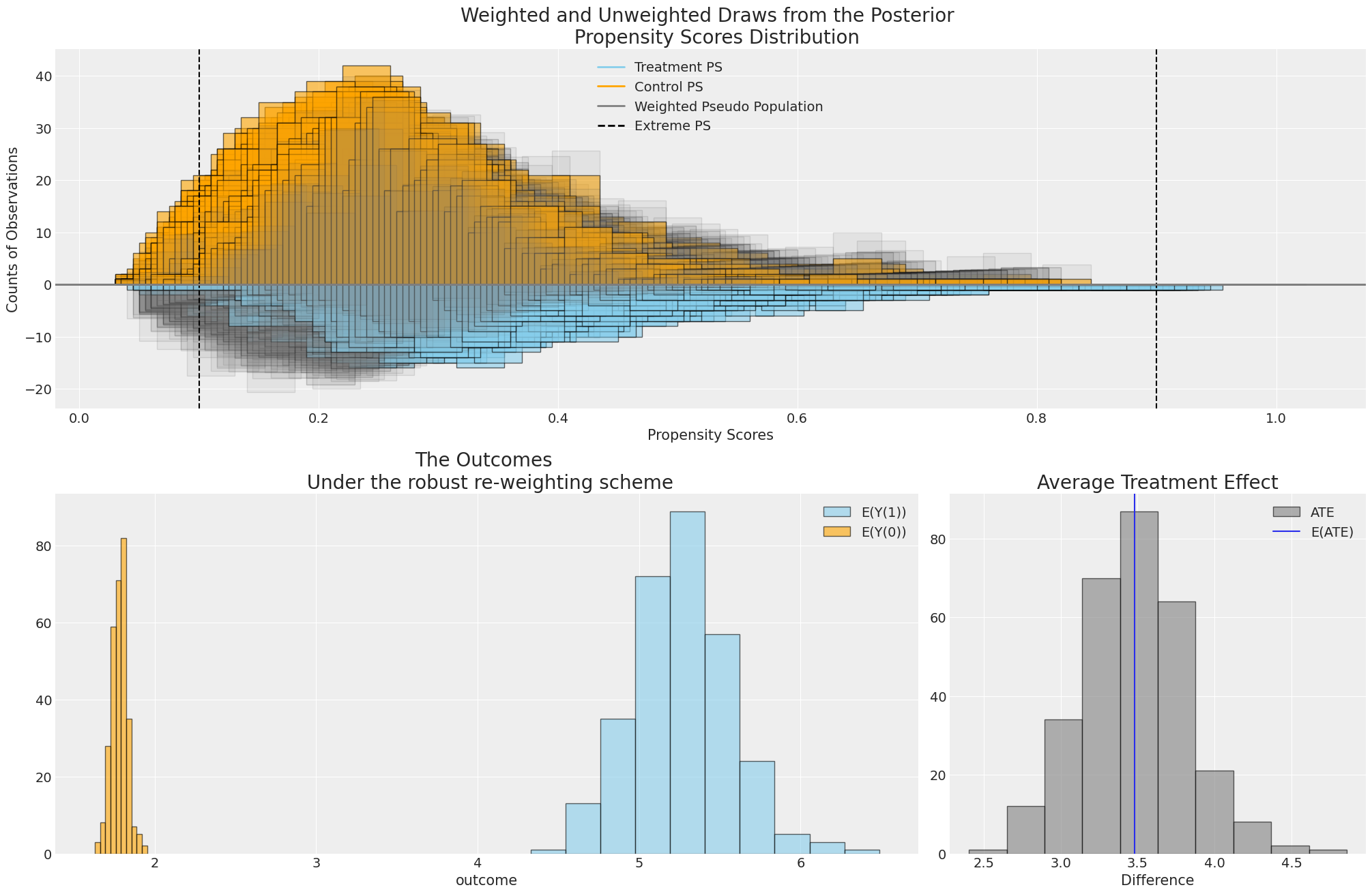
Two-Stage Outcome Modelling with CausalPy#
Next we show how to achieve these steps with the simpler CausalPy experiment API.
formula = """trt ~ 1 + age + race + sex + smokeintensity + smokeyrs + wt71 + active_1 + active_2 +
education_2 + education_3 + education_4 + education_5 + exercise_1 + exercise_2"""
df_standardised = (df - df.mean(axis=0)) / df.std(axis=0)
df_standardised["trt"] = df["trt"]
df_standardised["outcome"] = df["outcome"]
result = cp.InversePropensityWeighting(
df_standardised,
formula=formula,
outcome_variable="outcome",
weighting_scheme="robust", ## Will be used by plots after estimation if no other scheme is specified.
model=cp.pymc_models.PropensityScore(
sample_kwargs={
"chains": 4,
"tune": 2000,
"draws": 10000,
"target_accept": 0.95,
"random_seed": 18,
"progressbar": False,
"mp_ctx": "spawn",
},
),
)
result
Show code cell output
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_std]
Sampling 4 chains for 2_000 tune and 10_000 draw iterations (8_000 + 40_000 draws total) took 26 seconds.
Sampling: [beta_std, t_pred]
Sampling: [t_pred]
<causalpy.experiments.inverse_propensity_weighting.InversePropensityWeighting at 0x29d4acd70>
Comparing Inverse Propensity Score Weighting and Covariate Adjustment#
The two step procedure doesn’t jusst apply for regression adjustment methods as we’ve seen here, but can be used to apply inverse weighting techniques too.
result.plot_ate(result.idata);
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/IPython/core/events.py:82: UserWarning: Creating legend with loc="best" can be slow with large amounts of data.
func(*args, **kwargs)
/Users/nathanielforde/mambaforge/envs/CausalPy/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Creating legend with loc="best" can be slow with large amounts of data.
fig.canvas.print_figure(bytes_io, **kw)
which can be compared against the two-step regression adjustment here.
idata_outcome_cp, model_outcome_cp = result.model.fit_outcome_model(
result.X_outcome,
result.y,
result.coords,
priors={"b_outcome": [0, 3], "sigma": 10, "beta_ps": [0, 10]},
noncentred=True,
normal_outcome=True,
)
Show code cell output
Sampling: [beta_ps, beta_std, like, sigma]
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta_std, beta_ps, sigma]
Sampling 4 chains for 2_000 tune and 10_000 draw iterations (8_000 + 40_000 draws total) took 47 seconds.
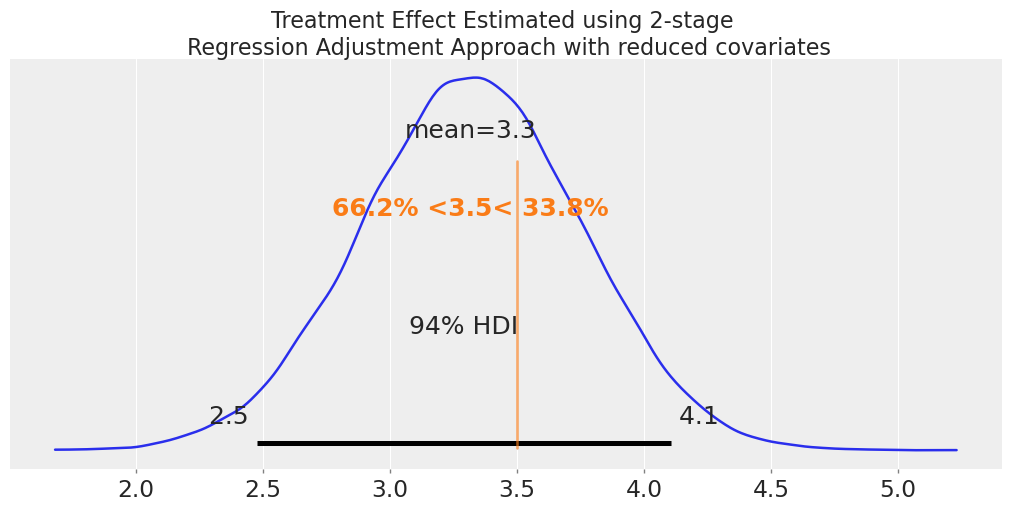
Yielding similar, but not identical results.
az.summary(idata_outcome_cp, var_names=["beta_"])
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| beta_[Intercept] | 2.093 | 1.344 | -0.434 | 4.612 | 0.014 | 0.009 | 9380.0 | 14843.0 | 1.0 |
| beta_[age] | -2.210 | 0.721 | -3.543 | -0.835 | 0.007 | 0.004 | 10668.0 | 17142.0 | 1.0 |
| beta_[race] | 0.151 | 0.312 | -0.445 | 0.727 | 0.003 | 0.002 | 12175.0 | 20768.0 | 1.0 |
| beta_[sex] | -0.797 | 0.409 | -1.562 | -0.024 | 0.004 | 0.002 | 11010.0 | 17907.0 | 1.0 |
| beta_[smokeintensity] | 0.178 | 0.337 | -0.469 | 0.797 | 0.003 | 0.002 | 12015.0 | 19490.0 | 1.0 |
| beta_[smokeyrs] | 0.467 | 0.602 | -0.682 | 1.575 | 0.006 | 0.003 | 11849.0 | 19291.0 | 1.0 |
| beta_[wt71] | -1.509 | 0.214 | -1.920 | -1.112 | 0.001 | 0.001 | 33903.0 | 28828.0 | 1.0 |
| beta_[active_1] | -0.539 | 0.214 | -0.930 | -0.122 | 0.001 | 0.001 | 29101.0 | 29625.0 | 1.0 |
| beta_[active_2] | -0.116 | 0.207 | -0.512 | 0.266 | 0.001 | 0.001 | 31383.0 | 29074.0 | 1.0 |
| beta_[education_2] | 0.416 | 0.253 | -0.071 | 0.881 | 0.002 | 0.001 | 25487.0 | 28436.0 | 1.0 |
| beta_[education_3] | 0.398 | 0.275 | -0.137 | 0.904 | 0.002 | 0.001 | 23112.0 | 26560.0 | 1.0 |
| beta_[education_4] | 0.360 | 0.249 | -0.117 | 0.821 | 0.002 | 0.001 | 20161.0 | 26766.0 | 1.0 |
| beta_[education_5] | 0.030 | 0.302 | -0.514 | 0.624 | 0.002 | 0.001 | 15996.0 | 23783.0 | 1.0 |
| beta_[exercise_1] | 0.209 | 0.279 | -0.317 | 0.737 | 0.002 | 0.001 | 20495.0 | 26199.0 | 1.0 |
| beta_[exercise_2] | 0.272 | 0.332 | -0.336 | 0.913 | 0.003 | 0.002 | 14760.0 | 21435.0 | 1.0 |
| beta_[trt] | 3.318 | 0.434 | 2.476 | 4.105 | 0.002 | 0.002 | 40864.0 | 30723.0 | 1.0 |
ax = az.plot_posterior(
idata_outcome_cp,
var_names=["beta_"],
coords={"outcome_coeffs": ["trt"]},
figsize=(10, 5),
ref_val=3.5,
)
ax.set_title(
"Treatment Effect Estimated using 2-stage \n Regression Adjustment Approach with reduced covariates"
);
Conclusion: Modularity as Causal Discipline#
When attempting to estimate treatment effects using Bayesian inference, a natural but risky strategy is to fit a joint model for both the treatment assignment and the outcome. That is, to specify a full model and infer the parameters of both components simultaneously.
However, this joint approach introduces a feedback loop: the outcome \(Y\) can influence the estimation of the treatment mechanism \(P(T | X)\). This violates the original logic of design-based inference, where treatment assignment should be modeled independently of the observed outcomes. This phenomenon is often subtle but can lead to biased treatment effect estimates.
Across several examples, we have shown that fitting a full joint model distorts the treatment effect estimate relative to a two-step (modular) approach.
In other cases, joint and modular approaches yield nearly identical estimates — usually when the outcome is well-identified from covariates alone. With these observations in scope, we recommend that practitioners generally follow a two-step or modular approach. Either two-stage inverse propensity score weighting or regression adjustment with the propensity score as an additional covariate. Both methods are available now in CausalPy.
Framed this way we can see that joint model violates the temporal precedence of the treatment assignment and outcome process. The 2-stage Bayesian procedures ensure that the causal ordering encoded in the actual data generating process is respected in the estimation process. The confounding adjustment achieved with propensity score must occur without access to information about the outcome. A well-specified propensity score model can substantially improve causal estimates (as we’ve seen), especially when the outcome model is weak or mis-specified. This allows for a form of doubly-robust inference as discussed in [Aronow and Miller, 2019] and [Fan et al., 2023]. Propensity scores do not only serve to reduce dimensionality; they formalize the treatment mechanism and encode information that the outcome model might fail to recover. This explains their continued prominence in modern causal inference and usefulness in the Bayesian setting.
References#
P Aronow and B Miller. Foundations of Agnostic Statistics. Cambridge University Press, 2019.
Li Fan, Ding Peng, and Mealli Fabrizia. Bayesian causal inference: a critical review. Philosophical Transactions of the Royal Society, 2023.
G. J. Griffith, T. T. Morris, M. J. Tudball, A. Herbert, G. Mancano, L. Pike, G. C. Sharp, J. Sterne, T. M. Palmer, G. Davey Smith, K. Tilling, L. Zuccolo, N. M. Davies, and G. & Hemani. Collider bias undermines our understanding of covid-19 disease risk and severity. Nature communications, 2020.
Miguel A. Hernan. Causal Inference: What If. CRC Press TBC, Boca Raton, 2024.
Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,xarray
Last updated: Tue Jul 29 2025
Python implementation: CPython
Python version : 3.13.5
IPython version : 9.4.0
pytensor: 2.31.7
xarray : 2025.7.0
matplotlib: 3.10.3
arviz : 0.21.0
pandas : 2.3.1
causalpy : 0.4.2
patsy : 1.0.1
pymc : 5.23.0
numpy : 2.3.1
Watermark: 2.5.0